AI LAB/🦜 TTS
3. [음성합성] cp949 codec can't encode character
728x90
https://doctorson0309.tistory.com/432
위의 글을 읽었다면, 음성 데이터를 다운을 시도하였을 것입니다.
그러나 간혹 아래와 같은 에러에 직면할 수도 있습니다.
'cp949' codec can't encode character '\xa0'

이것은 파일 열기와 관련된 파이썬 코드에 인코딩을 안 넣었다는 의미입니다.
더 확실하게 설명하자면, UTF-8로 저장되어 있는 텍스트 파일을 열라고 시켰는데
파이썬이 싫다고 에러를 뱉은 것입니다. 파이썬은 ANSI를 좋아하기 때문입니다.
(??) ㅎㅎㅎ

텍스트 파일을 ANSI로 바꿔도 에러는 해결될 테지만, 아래와 같이 하는 것이 더 좋습니다.
기존에 아래와 같이 코딩되어 있을 것입니다.
open("test1.txt", mode='w')
그것을 아래처럼 바꾸시면 됩니다.
open("test1.txt", mode='w', encoding='utf8')
mode가 wb인 곳에는 encodeing을 적용시키면 안됩니다.
binary mode doesn't take an encoding argument라는 에러가 발생하고 검색의 시공에서 빠지게 될 것입니다.
wb가 뭐냐면, 바이너리파일 즉 이미지를 의미합니다. 이미지에 인코딩을 적용했으니 파이썬이 화낸 것입니다.

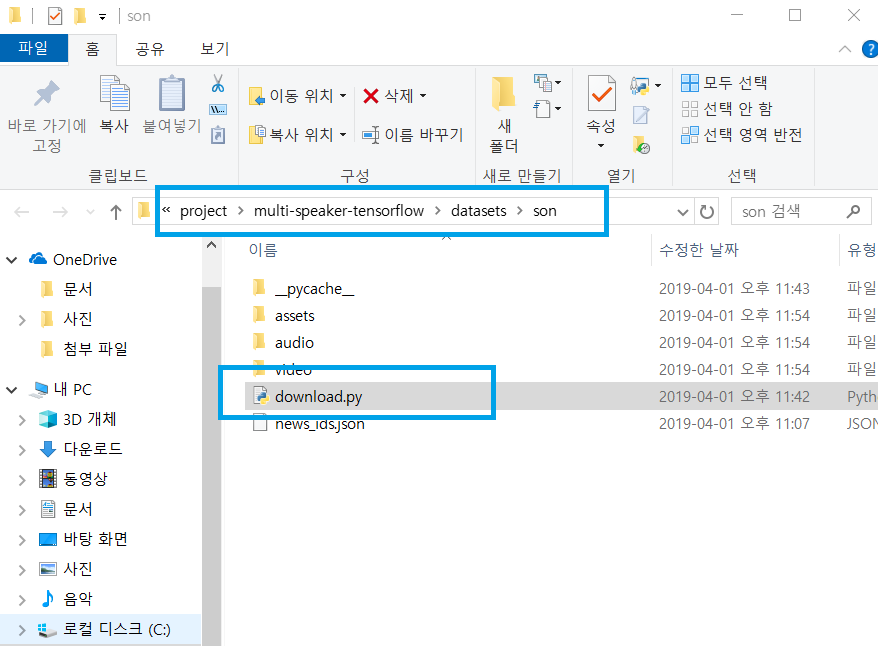
아무튼 각설하고 적절히 수정한 download.py를 공유합니다.
이것은 프로젝트 최 상위 디렉터리 -> datasets -> son 폴더안에 존재하는 download.py입니다.
아래의 링크를 참고하면 더 자세한 내용을 알 수 있습니다.
https://stackoverflow.com/questions/43821262/unicodeencodeerror-cp949-codec-cant-encode-character
혹시 아래의 명령어를 입력하다가 cp949 codec can't encode character에러를 직면하셨을 경우
python -m recognition.alignment --recognition_path "./datasets/son/recognition.json" --score_threshold=0.5
utf 인코팅 옵션을 포함시켜서 다시 시도해보세요.
python -m recognition.alignment --recognition_path "./datasets/son/recognition.json" --score_threshold=0.5 --recognition_encoding="utf-8"

혹시 에러가 난다면, 에러코드를 댓글에 적어주시면 됩니다.
추가로 질문사항이 있다면 댓글 남겨주세요. 감사합니다.
반응형
'AI LAB > 🦜 TTS' 카테고리의 다른 글
| 6. [음성합성] IndexError list index out of range 해결 (0) | 2019.04.07 |
|---|---|
| 5. [음성합성] recognition.google --audio_pattern (0) | 2019.04.06 |
| 4. [음성합성] INVALID_ARGUMENT, WAV header indicates 해결 (0) | 2019.04.06 |
| 2. [음성합성] 데이터 셋 다운로드 오류 대처 (0) | 2019.04.01 |
| 1. [음성합성] 개발환경 구축 및 패키지 소프트웨어 설치 (0) | 2019.04.01 |
Contents
소중한 공감 감사합니다